This grand challenge aims to advance large-scale human-centric video analysis in complex events using multimedia techniques. We propose the largest existing dataset (named as Human-in-Events or HiEve) for understanding human motion, pose, and action in a variety of realistic events, especially crowd & complex events. Four challenging tasks are established on our dataset, which encourages researches to address the very challenging and realistic problems in human-centric analysis. Our challenge will benefit researches in a wide range of multimedia and computer vision areas including multimedia analysis and multimedia content analysis.
• Dataset
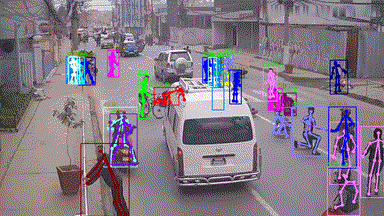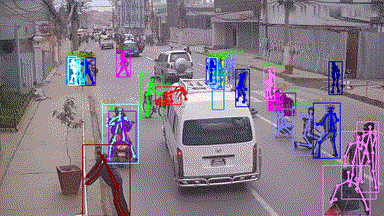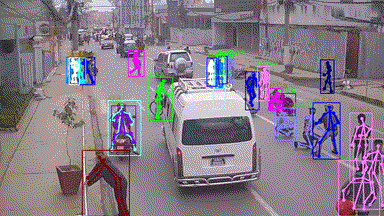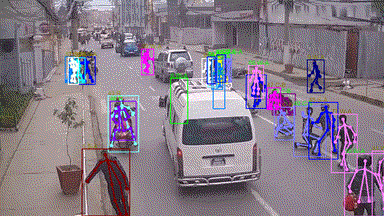
In this grand challenge, we focus on very challenging and realistic tasks of human-centric analysis in various crowd & complex events, including subway getting on/off, collision, fighting, and earthquake escape (cf. Figure. 1). To the best of our knowledge, few existing human analysis approaches report their performance under such complex events. With this consideration, we further propose a dataset (named as Human-in-Events or HiEve) with large-scale and densely-annotated labels covering a wide range of tasks in human-centric analysis (1M+ poses and 56k+ action labels, cf. Table 1).
Our HiEve dataset covers a wide range of human-centric understanding tasks including motion, pose, and action, while the previous workshops only focus on a subset of our tasks. Compared with the related workshops & challenges, our challenge has the following unique characteristics:
• Our challenge covers a wide range of human-centric understanding tasks including motion, pose, and action, while the previous workshops only focus on a subset of our tasks (cf. Table 1).
• Our challenge has substantially larger data scales, which includes the currently largest number of poses (>1M), the largest number of complex-event action labels (>56k), and one of the largest number of trajectories with long terms (with average trajectory length >480).
• Our challenge focuses on the challenging scenes under various crowd & complex events (such as dining, earthquake escape, subway getting-off, and collision, cf. Figure 1), while the related workshops are mostly related to normal or relatively simple scenes.
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |
| Dataset | # pose | # box | # traj.(avg) | # action | pose track | surveillance | complex events |
| MSCOCO | 105,698 | 105,698 | NA | NA | × | × | × |
| MPII | 14,993 | 14,993 | NA | 410 | × | × | × |
| CrowdPose | ~80,000 | ~80,000 | NA | NA | × | × | × |
| PoseTrack | ~267,000 | ~26,000 | 5,245(49) | NA | √ | × | × |
| MOT16 | NA | 292,733 | 1,276(229) | NA | × | √ | × |
| MOT17 | NA | 901,119 | 3,993(226) | NA | × | √ | × |
| MOT20 | NA | 1,652,040 | 3,457(478) | NA | × | √ | × |
| Avenue | NA | NA | NA | 15 | × | √ | × |
| UCF-Crime | NA | NA | NA | 1,900 | × | √ | √ |
| HiEve (Ours) | 1,099,357 | 1,302,481 | 2687(485) | 56,643 | √ | √ | √ |